[latexpage]
Sebelum lebih jauh kedalam programming, pada lesson Komponen Artificial Neural Network (ANN) akan membahas struktur yang membentuk ANN.
Walaupun tidak sama, ANN adalah sistem komputer yang mencoba meniru cara kerja biological neural network. Berikut komponen untuk membentuk ANN:
Layers
Layer adalah komponen utama dari ANN. Operasi Linear ditambahkan operasi non-liniearity akan membentuk layer.
Pada lesson sebelumnya, kita sudah membuat model linear, dimana input diproses oleh operasi linear dan menghasilkan output. Ini adalah jenis neural network yang paling sederhana, tanpa layer atau tanpa depth.
Pada neural network, sebuah output akan menjadi input bagi layer berikutnya. Berikut model ANN dan istilah yang perlu dipahami.

- Width, adalah jumlah hidden unit dalam hidden layer, pada gambar diatas berarti width adalah 9.
- Depth, adalah jumlah hidden layer, pada gambar diatas adalah 3.
- Hyperparameter, adalah parameter yang kita tentukan untuk membuat ANN, dalam hal ini width dan depth. Hyperparameter lainnya adalah learning rate.
- Input Layer, data training yang diinput ke model dalam hal ini kita memiliki 8 input. Pada TensorFlow, ini disimpan dalam placeholder untuk input.
- Hidden layer, layer yang berada diantara input dan output layer, jumlahnya menunjukan depth dari ANN.
- Output layer, atau hasil perhitungan model yang akan dibandingkan terhadap target. Dalam hal ini output ada 4.
Dari contoh gambar diatas, Pada layer input, data diinput ke model. Lalu diproses dengan operasi linear dan non-linear menghasilkan ouput, dan akan digunakan sebagai input bagi layer berikutnya.
Menambahkan hidden layer dapat dilakukan berulang-ulang tergantung kebutuhan kita. Tentunya makin depth model, resource komputer yang dibutuhkan akan lebih besar (memory, computing power).
Perhatian, hyperparameter berbeda dengan parameter. Parameter adalah weights dan biases, nilainya dihitung oleh model. Sementara hyperparameter adalah nilai yang kita tentukan saat membuat ANN.
Activation Functions
Non-linearity yang ditambahkan setelah perhitungan linear, pada machine-learning disebut sebagai Activation Functions. Activation functions yang sering digunakan:
| Nama Fungsi | Formula | Range |
| Sigmoid (logistic function) | $\sigma(a) = \frac{1}{1+e^{-a}}$ | [0, 1] |
| Tanh (hyperbolic tangent) | $\tanh(a) = \frac{e^a-e^{-a}}{e^a+e^{-a}}$ | [-1, 1] |
| ReLu (Rectified Linear unit) | Relu(a) = max(0, a) | [0, $\infty$] |
| Softmax | $\sigma_i(a) = \frac{e^{a_i}}{\sum_j e^{a_j}}$ | [0, 1] |
Softmax
Semua activation function diatas mempunyai kegunaan masing-masing, dibahas softmax karena berhubungan dengan lesson sebelumnya saat membahas cross-entropy loss.
Softmax akan mentransform input menjadi probability distribution. Mari kita bahas menggunakan contoh pengandaian dan penyerdehanaan untuk menjelaskan konsep softmax.
Misal, persamaan a = xw + b dengan a = [-0.21, 0.47, 1.72], dan output y adalah y = softmax(a).
- $\sigma_i(a) = \frac{e^{a_i}}{\sum_j e^{a_j}}$
- Hitung dahulu pembaginya, $e^{-0.21} + e^{0.47} + e^{1.72}$ = 8
- $softmax(a) = [\frac{e^{-0.21}}{8}, \frac{e^{0.47}}{8}, \frac{e^{1.72}}{8}]$
- maka y = [0.1, 0.2, 0.7]
- Vector diatas menunjukan 10%, 20% dan 70% probability.
Tentu masih ingat akan lesson yang membahas classification kucing, anjing dan kuda. Softmax dapat digunakan untuk menentukan seberapa yakin model mengenali image dan melakukan klasifikasi.
Backpropagation
Backpropagation adalah prosedur untuk menghitung error pada hidden layer. Prosedur ini dilakukan secara otomatis oleh library TensorFlow. Kita akan bahas sedikit agar paham apa yang terjadi dibelakang layar.
Mari kita mulai dari Forward propagation, adalah prosedur saat kita memasukan data input ke system. Data diterima, diproses oleh hidden layer, hingga keluar menjadi output. Lalu output akan dibandingkan terhadap target untuk menghitung error.
Lalu TensorFlow akan melakukan backpropagation untuk mengupdate parameter (biases dan weight) agar error epoch berikutnya bisa dimiminalkan.
Karena deepnet, maka perhitungan menjadi cukup kompleks karena harus menghitung semua biases dan weights dari hidden layer.
Selain itu hidden layer tidak memiliki target (ingat, target adalah data yang akan dibandingkan dengan output, berasal dari data input). Oleh karena itu error yang digunakan adalah error pada output layer, dimana hidden unit tersebut ikut berkontribusi melakukan perhitungan.
Agar lebih mudah dipahami, kita gunakan gambar yang menggambarkan deepnet sederhana dengan 1 hidden layer. Weight dibedakan notasinya agar bisa lebih jelas.
- x1, x2 adalah input node.
- w11, w12, … w23 adalah weight dari input ke hidden node.
- h1, h2, h3 adalah hidden node.
- u11, u12, … u 32 adalah weigth dari hidden ke output node.
- y1, y2 adalah output.
- e1, e2 adalah error.
- t1, t2 adalah target.
u11 berkontribusi dalam error e1, oleh karena itu dengan menggunakan e1, system akan melakukan backpropagation dan mengupdate u11 berdasarkan e1.

Sementara w11 digunakan untuk menghitung h1, dan h1 berkontribusi pada error e1 dan e2. oleh karena itu untuk melakukan perhitungan error dan mengupdate w11, digunakan e1 dan e2 (lihat gambar dibawah).
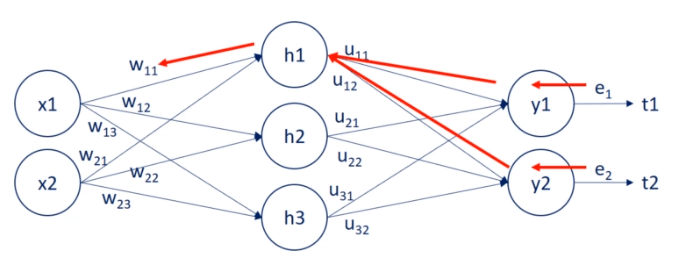
Dengan menggunakan weight u11 dan u12 untuk mengukur kontribusi masing-masing weight terhadap error. Weight w11 akan diadjust berdasarkan kontribusi yang lebih besar terhadap error.
Dapat dibayangkan bila model yang kita rancang memiliki banyak hidden layer dengan hidden node yang banyak, akan sangat rumit.
Seperti yang sudah dikatakan diawal, backpropagation sudah dilakukan secara otomatis oleh TensorFlow, jadi kita tidak perlu khawatir dengan kerumitan diatas.
1 thought on “Komponen Artificial Neural Network”
Comments are closed.