Lesson web scraping IMDB posters akan mengambil poster dari top 250 movies. Pada lesson ini dibatasi 5 poster, jika ingin mendownload semua poster, hapus bagian if statement.
Pendekatan yang dilakukan adalah, program pertama akan akses web imdb lalu download html kedalam teks file. Setelah itu file teks ini akan dibaca oleh program kedua untuk mendownload posters.
Berikut adalah script yang digunakan untuk download halaman 250 top movie dari imdb dengan url : https://www.imdb.com/chart/top?ref_=nv_mv_250
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import os
from bs4 import BeautifulSoup
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--window-size=1920x1080")
chrome_driver = os.getcwd() +"\\chromedriver.exe"
url = 'https://www.imdb.com/chart/top?ref_=nv_mv_250'
driver = webdriver.Chrome(chrome_options=chrome_options, executable_path=chrome_driver)
driver.get(url)
soup = BeautifulSoup(driver.page_source,'lxml')
with open('imdb.txt', 'w', encoding='utf-8') as f_out:
f_out.write(soup.prettify())
driver.quit()
Berikut link image poster thumbnail dan versi poster.
Nama file thumbnail :
https://m.media-amazon.com/images/M/MV5BMDFkYTc0MGEtZmNhMC00ZDIzLWFmNTEtODM1ZmRlYWMwMWFmXkEyXkFqcGdeQXVyMTMxODk2OTU@.V1_UY67_CR0,0,45,67_AL.jpg
Nama file poster besar:
https://m.media-amazon.com/images/M/MV5BMDFkYTc0MGEtZmNhMC00ZDIzLWFmNTEtODM1ZmRlYWMwMWFmXkEyXkFqcGdeQXVyMTMxODk2OTU@.V1_AL.jpg
Jadi untuk mendapatkan link image poster, cukup dengan memotong bagian _UY67_CR0,0,45,67
FIle image akan disimpan di hardisk dengan menggunakan informasi nama movie berserta peringkat dan tahun tampil. Untuk mendapatkan data tersebut lihat gambar dibawah.
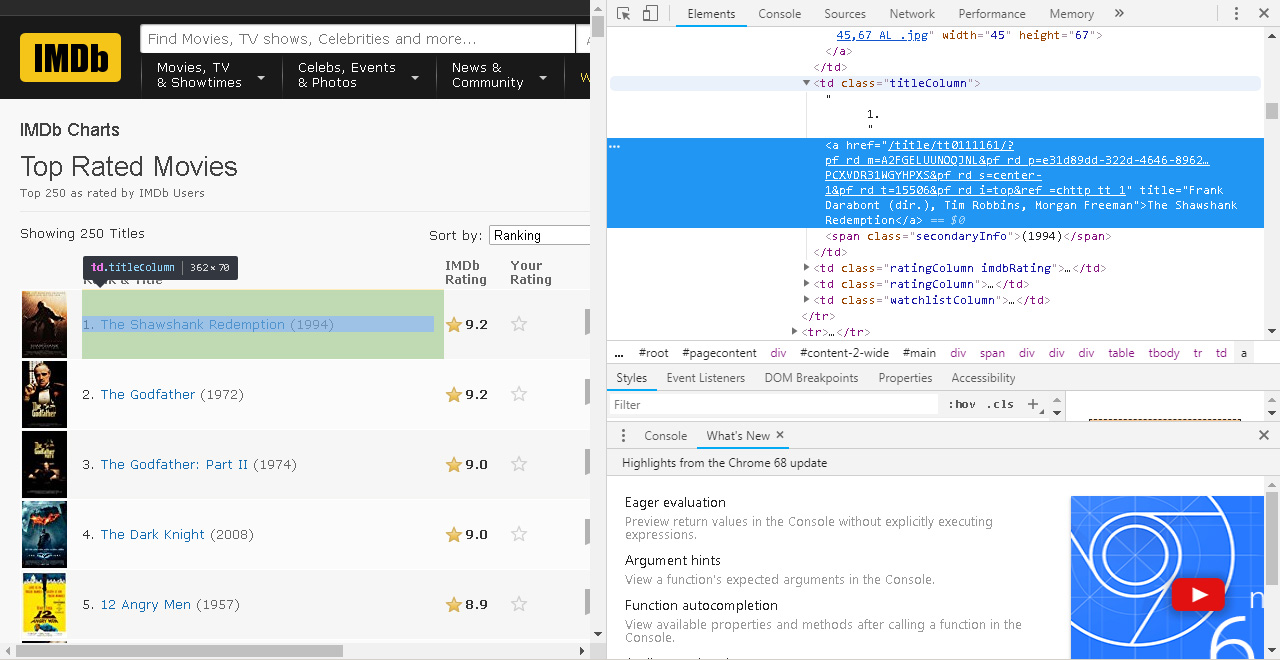
Berikut program untuk mendownload poster dari IMDB Top 250 Movies
import requests
from bs4 import BeautifulSoup
import os
def read_file():
file = open(current_path + '\\imdb.txt')
data = file.read()
file.close()
return data
current_path = os.path.dirname(os.path.abspath(__file__))
soup = BeautifulSoup(read_file(),'lxml')
poster_col = soup.find('table', class_ = 'chart').find_all('td', class_='posterColumn')
poster_img = [td.a.img['src'] for td in poster_col]
d_movall = {}
i=0
mov_col = soup.find('table', class_='chart').find_all('td', class_='titleColumn')
for td in mov_col:
if i == 5:
break
full_title = (td.text.strip().replace('\n','').replace(' ',''))
rank = full_title.split('.')[0]
title = full_title.split('.')[1][:-6]
title = title.replace(':', '')
year = full_title.split('.')[1][-5:-1]
s = rank + '-' + title + '-' + year
#a = td.a['href']
#lst_movdet.append(s)
jpg_link = poster_img[i].split('V1')[0] + 'V1_.jpg'
d_movall[s] = jpg_link
i += 1
with open(current_path + '\\imgdump\\' + s +'.jpg', 'wb') as f_out:
f_out.write(requests.get(jpg_link).content)