Pada modul ini kita akan mulai coding, dimulai dengan scrapper sederhana. Web imdb.com akan kita jadikan target scrapping. Data yang akan diambil adalah: Judul, Rating, Poster, Total Rating dan Release Date. Kemudian menyimpannya dalam file csv.
Untuk file csv, kita akan gunakan library json2csv. Library ini untuk mengubah file json menjadi csv. Untuk dokumentasi detail lihat disini.
Untuk instalasi gunakan perintah npm install –save json2csv
Untuk akses file system kita gunakan library default dari Node.js yaitu fs. Dokumentasi detail silakan dilihat disini.
Code
const requestPromise = require('request-promise');
const cheerio = require('cheerio');
const fs = require('fs');
const Json2csvParser = require('json2csv').Parser;
const URLS = [
{
uri: 'https://www.imdb.com/title/tt8579674/',
id: '1917'
},
{
uri: 'https://www.imdb.com/title/tt7545266/',
id: 'like_a_boss'
}
];
(async () => {
let moviesData = [];
for(let movie of URLS) {
const response = await requestPromise({
uri: movie.uri,
headers: {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'en-US,en;q=0.9,fr;q=0.8,ro;q=0.7,ru;q=0.6,la;q=0.5,pt;q=0.4,de;q=0.3',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Host': 'www.imdb.com',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
},
gzip: true
}
);
let $ = cheerio.load(response);
let title = $('div[class="title_wrapper"] > h1').text().trim();
let rating = $('div[class="ratingValue"] > strong > span').text();
let poster = $('div[class="poster"] > a > img').attr('src');
let totalRatings = $('div[class="imdbRating"] > a').text();
let releaseDate = $('a[title="See more release dates"]').text().trim();
let popularity = $('#title-overview-widget > div.plot_summary_wrapper > div.titleReviewBar > div:nth-child(5) > div.titleReviewBarSubItem > div:nth-child(2) > span').text().trim();
moviesData.push({
title,
rating,
poster,
totalRatings,
releaseDate
});
}
const json2csvParser = new Json2csvParser();
const csv = json2csvParser.parse(moviesData);
fs.writeFileSync('./data.csv', csv, 'utf-8');
console.log(csv);
})()
Pembahasan code
Load library yang diperlukan, yaitu request-promise, cheerio, fs dan json2csv.
const request = require('request-promise');
const cheerio = require('cheerio');
const fs = require('fs');
const Json2csvParser = require('json2csv').Parser;
Setelah itu, buat array yang berisi link film yang akan kita scrap dari web imdb.
const URLS = [
{uri: 'https://www.imdb.com/title/tt8579674/'},
{uri: 'https://www.imdb.com/title/tt7545266/'}
];
Isi array diloop sebagai input untuk melakukan request ke server imdb.com
for(let movie of URLS) {
//code scrapping ada disini
//pembahasan code pada loop ini akan dijelaskan dibawah
}
Kita akan melakukan request yang hasilnya akan ditampung ke variable response. Agar server target melihat request yang datang seperti dilakukan dari browser, kita perlu mengatur header dari request.
Config lainya yang penting adalah gzip: true. Umumnya website meng-compress content request untuk menghemat network traffic.
const response = await request({
uri: movie.uri,
headers: {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'en-US,en;q=0.9,fr;q=0.8,ro;q=0.7,ru;q=0.6,la;q=0.5,pt;q=0.4,de;q=0.3',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Host': 'www.imdb.com',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
},
gzip: true
}
);
Load library cheerio untuk memparsing isi html (variable response). Untuk dokumentasi detail silakan kunjungi cheerio.js.org
let $ = cheerio.load(response);
Untuk mengambil konten dari html tag, kita menggunakan cheerio selector. Format cheerio selector adalah $( selector, [context], [root] ).
Cara kerja mengambil title dari imdb.com
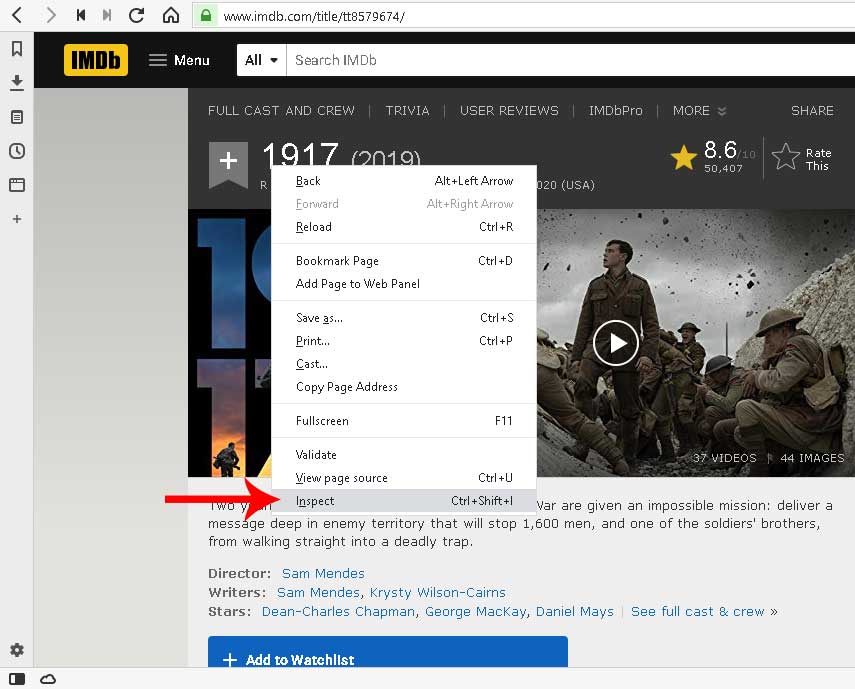
- Buka browser dengan alamat film yang kita inginkan. Contoh: https://www.imdb.com/title/tt8579674/
- Click kanan pada title film, pilih menu inspect. Panel developer tools akan tampil.(lihat gambar dibawah).
- Lalu cari tag yang yang unik yang akan mengembalikan title. (lihat gambar dibawah). Kita tidak bisa hanya menggunakan tag h1 yang berisi title. Karena h1 pada konten banyak. Karena itu kita gunakan div[class=”title_wrapper”] > h1. Ini akan menunjukan ke elemen kontainer title.
- Setelah tag diketahui, gunakan query selector untuk mengambil isi text. Lalu gunakan perintah trim() untuk membersihkan spasi.
- Code yang dibahas hanya untuk mengambil title, namun logikanya sama dengan data yang lainnya.
let title = $('div[class="title_wrapper"] > h1').text().trim();
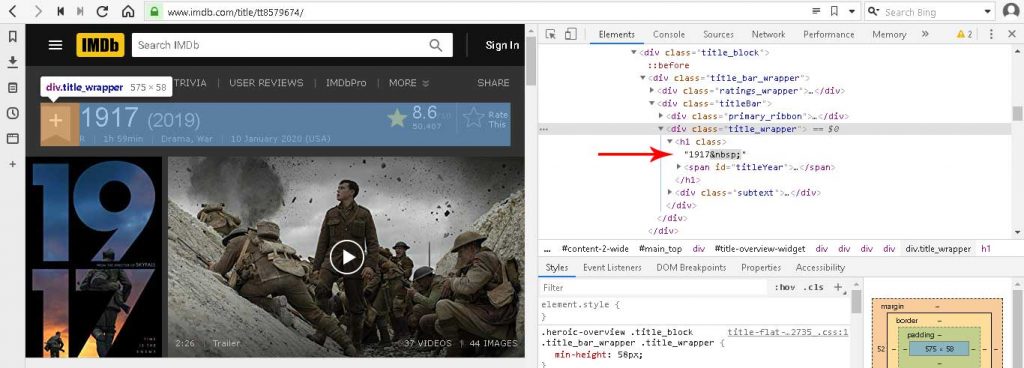
Lakukan hal yang sama untuk data lainnya yang akan discrap. Seperti tahun, rating dan lainnya.
Langkah berikutnya kita simpan data yang sudah diambil ke object JSON.
moviesData.push({
title,
rating,
poster,
totalRatings,
releaseDate
});
Langkah berikutnya adalah menyimpan data json kedalam bentuk csv. Proses ini tidak wajib, hanya sebagai contoh. Setelah data dikumpulkan, bisa disimpan dalam file, dengan salah satunya dengan format csv.
Karena sebelumnya kita menggunakan object json. Kita gunakan library Json2csv. Buat object json2csvParser, lalu gunakan object JSON dari variable moviesData untuk diparsing ke format csv.
Kita gunakan library filesystem (library standard dari node.js) untuk menulis ke file. Parameter yang dibutuhkan adalah nama file, format dan encoding.
const json2csvParser = new Json2csvParser();
const csv = json2csvParser.parse(moviesData);
fs.writeFileSync('./data.csv', csv, 'utf-8');
Kesimpulan
Jadi untuk melakukan scraping, kita perlu mengetahui element html mana yang akan kita pasing ke cheerio. Usahakan gunakan hirarki tag yang terpendek. Karena makin pendek, kemungkinan error (karena admin web target merubah isi html), akan lebih kecil, walaupun tidak ada jaminan.
Latihan
Coba ubah code diatas agar bisa menyimpan image poster.
TIPS:
- Gunakan library request (library default dari Node.js). Lihat dokumentasinya disini.
- Gunakan juga promise untuk memastikan proses download selesai.
Untuk code solusi dapat download disini.