[latexpage]
Gradient descent dan learning rate lanjutan akan membahas teknik gradient descent advanced yang umum digunakan. Masalah yang mungkin timbul saat melakukan optimization menggunakan gradient descent dan solusinya.
Gradient Descent, atau GD menggunakan nilai learning rate yang kecil. GD akan melakukan update weights setelah semua data training harus selesai diproses, atau setiap 1 epoch (iterasi). Karena learning rate yang kecil maka untuk mencapai minimum dibutuhkan proses yang lama.
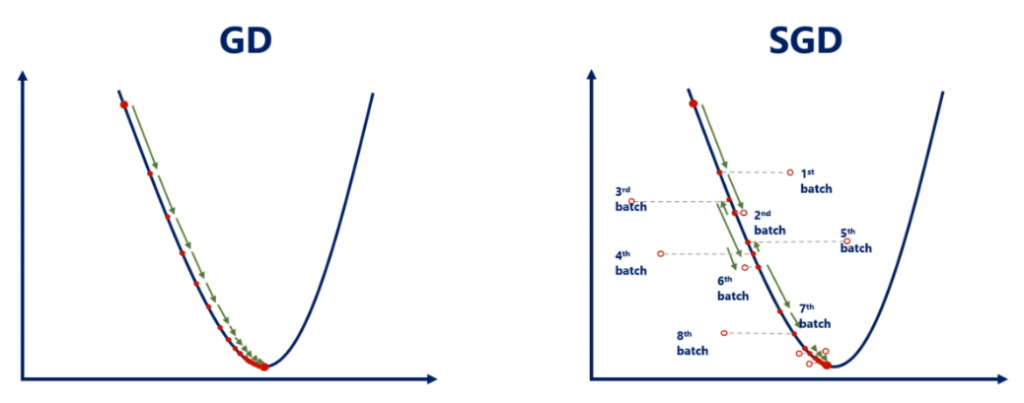
Stochastic Gradient Descent (SGD)
Adalah solusi untuk menyelesaikan issue dari GD. SGD akan melakukan update weight tanpa menunggu 1 epoch selesai. SGD menggunakan konsep yang mirip dengan batching dengan membagi data training menjadi beberapa batch. Weight akan diupdate dalam setiap batch selesai diproses.
Contoh, kita memiliki 10.000 data, dan menggunakan ukuran batch 1.000, maka ada 10 batch per epoch. Dalam 1 epoch, weight akan diupdate sebanyak 10 kali.
Namun SGD ada kekurangannya yaitu tingkat akurasi berkurang, namun tetap layak digunakan. Karena dibandingkan dengan kecepatan dalam melakukan optimization dan penggunaan resource hardware yang lebih optimum. Hal ini terbukti SGD sangat umum digunakan dikalangan praktisi data science.
Local Minimum
Pada prakteknya, loss function mungkin saja terdapat local minimum (lihat gambar). GD sangat rentan terhadap masalah ini, bahkan cukup sering GD mencapai local minimum, bukan global minimum.
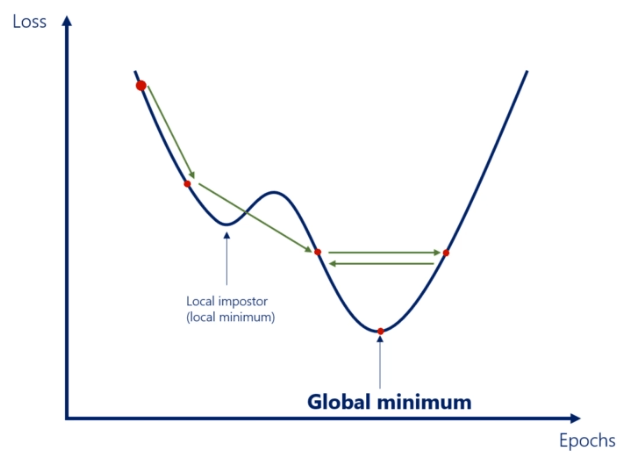
- Learning rate kecil, kemungkinan GD mencapai lokal minimum dan berhenti melakukan optimization.
- Learning rate besar, bisa saja melewati local minimum, namun bisa juga melewati global minimum, oscillate dan tidak pernah mencapai global minimum.
Note: Oscillate adalah kondisi dimana GD ping-pong berusaha mencari minimum.
Momentum
Adalah metoda yang ditambahkan pada GD untuk mencegah optimization berhenti pada local minimum.
Momentum dapat dianalogikan dengan menggelindingkan bola kedalam lembah. Makin cepat bola menggelinding, makin besar momentum.
Ketika bola mengenai ceruk kecil, karena momentum besar, maka bola tidak berhenti menggelinding. Bola akan terlempar dan terus menggelinding. Bola akan berhenti menggelinding ketika mencapai dasar lembah.
Dengan menambahkan momentum pada GD, maka local minimum dapat dihindari. Formula momentum adalah:
$w \leftarrow w – \eta \frac{\partial l}{\partial w}$
Selain itu kita juga menentukan ‘kecepatan bola’ dengan formula:
$w \leftarrow w(t) – \eta \frac{\partial l}{\partial w}(t) – \alpha \eta \frac{\partial l}{\partial w}(t-1)$
$\alpha$ (momentum coefficient) adalah hyperparameter yang dapat kita tentukan, umumnya 0.9
Learning Rate
Sejauh ini, telah kita pelajari, learning rate memiliki aturan:
- nilainya cukup kecil, hingga dapat mencapai minimum dan mencegah oscillate.
- nilainya cukup besar, agar optimum dapat dicapai dengan waktu yang masuk akal.
Nilai yang cukup kecil, namun cukup besar tentu suatu konsep yang kabur. Untuk mencapai konsep tersebut digunakan Learning rate schedules, yang memiliki aturan sebagai berikut:
- Tahap 1: Mulai dengan learning rate yang besar
- Tahap 2: Pada titik tertentu turunkan learning rate untuk mencegah oscillate
- Tahap 3: Pada akhir, learning rate yang sangat kecil untuk mendapatkan optimum yang akurat.
Ada dua pendekatan dalam melakukan scheduling learning rate.
Menentukan konstan, cara paling sederhana. Nilai learning rate diset dengan nilai tertentu dalam setiap tahap.
- Tahap 1: Learning rate 0.1 pada 5 epoch pertama
- Tahap 2: Learning rate 0.01 pada 5 epcoh berikutnya
- Tahap 3: Learning rate 0.001 sampai akhir.
Exponential schedule, adalah cara yang lebih pintar.
- Tahap 1, kita tentukan learning rate yang cukup besar, misal 0.1.
- Tahap berikutnya, learning rate akan diupdate setiap epoch dengan rule:
$\eta = \eta_0e^{-n/c}$
c (decay coefficient) adalah hyperparameter yang dapat kita atur. Tidak ada aturan baku untuk menentukan nilai c.