Scrapy Shell berfungsi seperti REPL Python, karena pada dasarnya adalah Python REPL. Scrapy shell sangat berguna untuk melakukan testing code secara cepat., misalnya testing XPath apakah returnnya sesuai harapan.
Scrapy shell dijalankan dari command prompt dengan perintah
scrapy shellJika Anda menginstall iPython, scrapy akan menggunakan iPython, namun jika tidak akan digunakan standard Python shell.
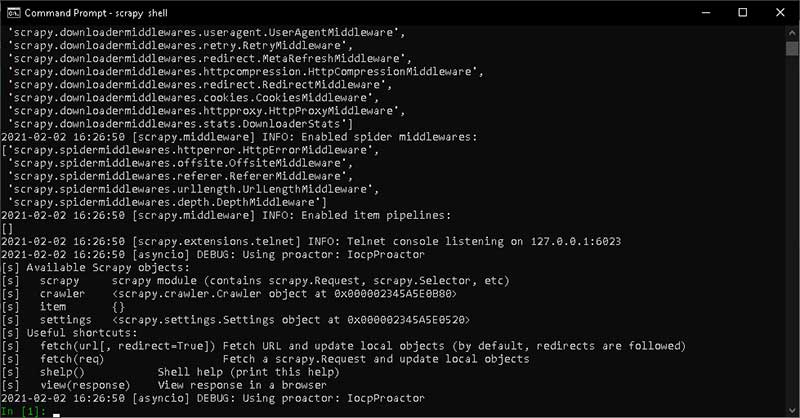
Setelah masuk kedalam shelll, Anda dapat melakukan path testing, pertama panggil perintah fetch.
fetch("http://quotes.toscrape.com/")JIka berhasil maka akan tampil log yang menunjukan status code 200.
2021-02-02 16:50:43 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://quotes.toscrape.com/> (referer: None)Setelah berhasil melakukan fetching, kita bisa mencoba XPath untuk ekstrak title dalam h1 tag Quotes to Scrape.
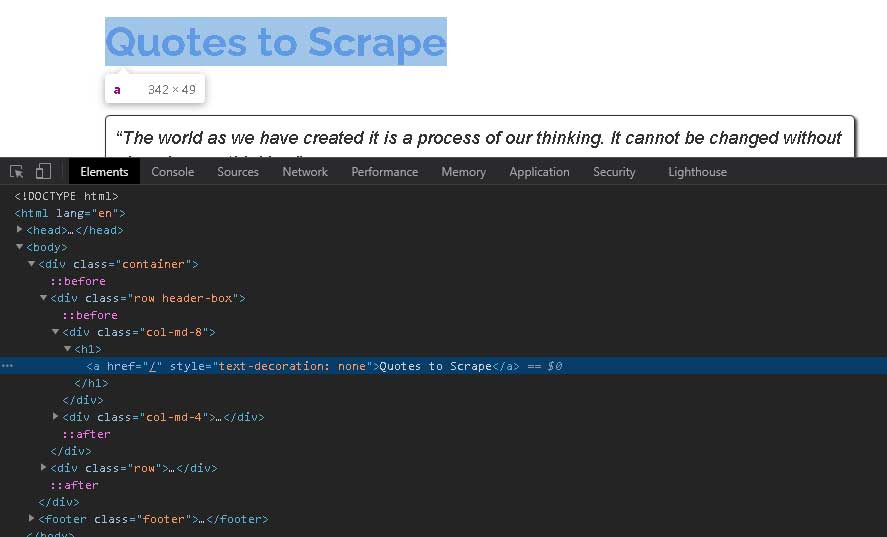
Pada shell, ketikan perintah response.xpath(‘//h1/a/text()’) untuk mendapatkan isi text dari h1 diatas.
Untuk extract data, gunakan perintah extract(). Return akan berupa python list berisi data unicode.
response.xpath('//h1/a/text()')
#output adalah
#Out[6]: [<Selector xpath='//h1/a/text()' data='Quotes to Scrape'>]
response.xpath('//h1/a/text()').extract()
#output adalah
#Out[7]: ['Quotes to Scrape']
Dapat dilihat dengan contoh diatas, scrapy shell sangat berguna untuk melakukan testing xpath yang akan kita gunakan.
Quiz, silakan bereksperimen untuk ekstrak data Top Ten Tags yang terletak dibagian kanan. Tips: gunakan xpath : //*[@class= (Jawaban bisa dilihat dibawah)
Implementasi XPath
Setelah dicoba melalui shell, mari kita pindahkan ke program quotes.py yang telah dibuat dengan perintah scrapy genspider pada modul sebelumnya. Lihat di https://skillplus.web.id/menggunakan-scrapy-cli/
import scrapy
class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['quotes.toscrape.com/']
start_urls = ['http://quotes.toscrape.com//']
def parse(self, response):
h1 = response.xpath('//h1/a/text()').extract()
tags = response.xpath('//*[@class="tag-item"]/a/text()').extract()
yield {'H1 Tag': h1, 'Tags' : tags}
Untuk menjalankan program, dari command prompt gunakan perintah berikut:
scrapy crawl nama_spider
#pada tutorial digunakan perintah
scrapy crawl quotesScrapy akan menampilkan log yang cukup panjang, perhatikan bagian dimana fungsi parse mengembalikan value untuk memastikan program berjalan dengan baik.
2021-02-02 17:47:48 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://quotes.toscrape.com//> (referer: None)
2021-02-02 17:47:48 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes.toscrape.com//>
{'H1 Tag': ['Quotes to Scrape'], 'Tags': ['love', 'inspirational', 'life', 'humor', 'books', 'reading', 'friendship', 'friends', 'truth', 'simile']}