Sebelum melakukan implementasi menggunakan Python, langkah pertama adalah Mendefinisikan Environment, yang terdiri dari States, Action dan Rewards.
States
States adalah input yang akan diterima oleh AI Model. Untuk kasus ini, adalah lokasi dari robot pada waktu t.
Karena akan digunakan Q-Learning, input tidak dapat berupa teks. Untuk itu kita perlu lakukan encoding untuk maping teks lokasi menjadi indeks.

Digunakan nilai interger 0-11 agar lebih mudah bekerja dengan matrix yang akan digunakan, yaitu matrix rewards dan matrix Q-Values.
Matrix akan menggunakan nilai state diatas. Contoh kolom pertama akan berisi 0 yang menunjukan lokasi A, dan kolom dua akan berisi nilai 1 yang menunjukan lokasi B dan seterusnya.
Actions
Pada contoh kasus kita, Action adalah langkah berikutnya yang dapat diambil oleh robot dari lokasi terakhir. Contoh, robot ada di lokasi J, actions yang dapat dilakukan adalah pergi ke I, F atau K.
Sama seperti State, actions juga akan diencode. Menggunakan contoh diatas, saat robot berada di lokasi J, actions yang dapat dilakukan adalah 5 (F), 8 (I) dan 10 (K).
Jadi total list of actions yang dapat digunakan AI adalah
actions = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]Pada lokasi tertentu, ada action yang tidak dapat dijalankan oleh robot. Menggunakan contoh diatas, ketika robot di lokasi J, robot dapat menjalankan actions 5, 8 dan 10, namun tidak dapat menjalankan actions lainnya.
Rewards
Rewards adalah komponen terakhir yang perlu kita definisikan dalam bentuk fungsi yang menerima input states s dan action a yang mengembalikan nilai numeric Req yang akan diterima AI.

Karena nilai state dan actions finite dan diskrit, cara terbaik untuk membuat reward function R adalah menggunakan matrix.
Matrix yang digunakan adalah 12 x 12 dimana baris menunjukan state, sementara column akan menunjukan actions. Jadi dari fungsi diatas,
- s akan berisi row index dari matrix,
- a akan berisi column index dari matrix
- r adalah cell dari indexes (s; a) dari matrix dengan isi nilai 0 atau 1 sesuai
Dengan ketentuan nilai reward seperti berikut
- 0: untuk aksi yang tidak bisa dijalankan.
- 1: untuk aksi yang bisa dijalankan.
Contoh untuk mengisi matrix, ketika di lokasi A, robot hanya dapat berjalan ke lokasi B. Karena Lokasi A adalah index 0 (baris pertama dari matrix) dan lokasi B adalah index 1 (kolom kedua dari matrix), maka isi matrix baris pertama hanya akan bernilai 1 pada kolom kedua, dan sisanya berisi nilai 0.

Berikut matrix reward untuk setiap state dan action:
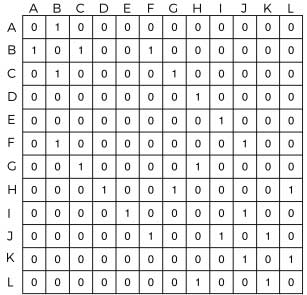
Sampai disini kita sudah selesai mendefinisikan matrix. Langkah terakhir adalah menentukan atribut high reward untuk lokasi prioritas utama.
Contoh kasus, lokasi G adalah prioritas utama, maka akan diupdate dengan nilai 1000 untuk menunjukan prioritas utama.

Sampai disini kita sudah selesai mendefinisikan environment yang terdiri dari state, action dan reward.
Sebelum melakukan implementasi menggunakan Q-Learning, pada modul selanjutnya kita akan membahas teori pendahuluan, agar dapat memahami Q-Learning lebih jelas.