Jika Anda sudah memahami konsep Q-Learning, modul ini dapat dilewati
Setelah mempelajari Bellman dan MDP, memahami Q-Learning akan lebih mudah.
Jika MDP menghitung nilai max dari state, Q-Learning akan menghitung nilai dari setiap aksi yang tersedia.

Berikut penurunan Q-Learning dari MDP.

Temporal Difference (TD)
Q-learning menggunakan Temporal Differences(TD) untuk melakukan estimasi nilai dari Q*(s,a)
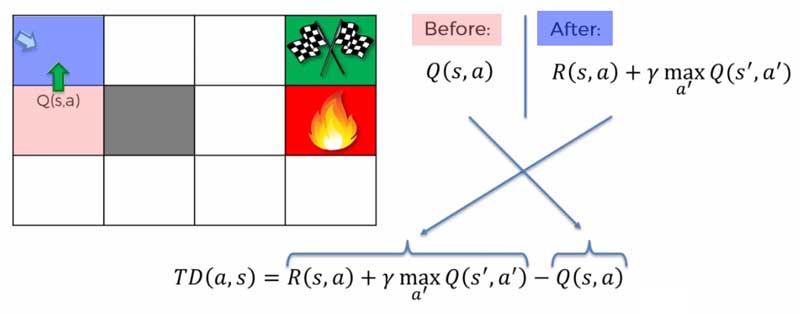
- Ketika agent berada pada block before (block merah muda), nilai Q dihitung dengan Q(s,a).
- Jika agent pindah ke block after (block biru), kita dapat hitung nilai Q dengan rumus diatas.
- TD adalah nilai perbedan dari perhitungan diatas.
Penerapannya pada perhitungan nilai Q adalah:

Anda tidak perlu menghapalkan rumus diatas. Tujuan dari modul ini adalah memberikan gambaran, bagaimana Q-Learning melakukan reinforcement learning jika dilihat dari sudut pandang matematis.
Jika Anda tertarik mempelajari lebih mendalam, berikut paper yang populer untuk sebagai additonal reading, https://link.springer.com/article/10.1007/BF00115009
1 thought on “Teori : Pengenalan Q-Learning”