Untuk memahami Q-Learning, Anda pelu memahami Bellman Equation dan MDP. Jika Anda sudah memahami konsep MDP, modul ini dapat dilewati.
Pada modul Pengenalan Bellman Equation, impresi yang kita dapat adalah Reinforcement Learning terlihat pasti, seperti peta. Pada kenyataanya tidak seperti itu.
Hal ini terjadi karena pada agent tidak diperkenalkan “randomness”, sementara pada dunia real, faktor randomness itu ada.
Deterministic dan Non-Deterministic Search
Randomness diperkenalkan kepada agent/model melalui non-deterministic search. Berikut perbandingan antara Deterministic vs Non-Deterministic Search.
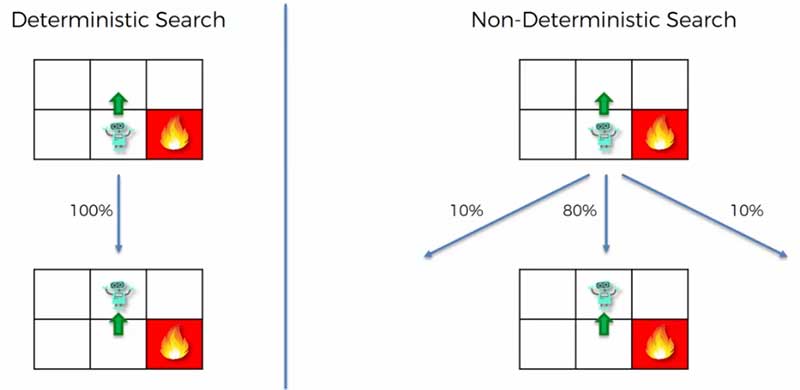
Pada deterministic search, opsi yang akan dilakukan adalah 100% atau pasti. Sementara pada non-deterministic, diperkenalkan probabilitas. Contoh, ada kemungkinanan agent bergerak ke kiri sebesar 10%, keatas 80% dan 10% kekanan.
Perhatian, contoh aksi dan nilai probabilitas bukan nilai fixed, hanya contoh.
Markov Decision Process
Penggunaan non-deterministic search diperkenalkan melalui Markov Decision Process.
Dengan mengambil sumber dari wikipedia, berikut definisi dari Markov Process.
Markov Process is is a stochastic model used to model pseudo-randomly changing systems. It is assumed that future states depend only on the current state, not on the events that occurred before it. -wikipedia.
Secara sederhana, markov process menunjukan event yang diambil oleh agent, berdasarkan state saat ini. State sebelumnya tidak mempengaruhi.
Sementara Markov Decision Process adalah
Provides a mathematical framework for modeling decision making in situations where outcomes are partly random and partly under the control of a decision maker. -wikipedia.
Jadi MDP adalah framework matematis untuk membuat model pengambil keputusan, dimana aksi yang dilakukan dipengaruhi oleh randomness dan pihak pengambil keputsan.
Jadi MDP akan menambahkan randomness pada Bellman Equation yang telah kita pelajari pada modul sebelumnya.

Kita tidak akan bahas proses perhitungan dari MDP karena sangat rumit. Sementara tujuan dari modul ini lebih ke memperkenalkan MDP. Oleh karena itu pada gambar dibawah akan digunakan nilai perkiraan.
Plan Vs Policy
Dengan menerapkan MDP, hasil perhitungan masing-masing state akan berubah. Berikut perbandingan antara Bellman dan MDP.

Pada Bellman Equation, pergerakan agent sudah pasti, berupa plan.
Sementara pada MDP, agent memiliki policy untuk mendapatkan reward maksimum.
Perhatikan pada block dengan value 0.39 dan 0.22. Agent akan menjauhi reward negatif (punishment), karena policy agent adalah mendapatkan reward maksimum.
Living Penalty
Living penalty bertujuan untuk mendapatkan policy reward maksimum. Dimana penerapannya adalah dengan memberikan reward negatif pada setiap block yang dilalui agent.
Karena tujuannya adalah mendapatkan reward maksimum, maka agent akan berusaha secepat mungkin mencapai tujuan, yaitu block reward +1.

Dengan mengubah nilai living penalty, akan membuat agent memiliki policy yang berbeda. Berikut perbandingannya.
Hal yang menarik, ketika nilai living penalty sangat tinggi, R(s) = -2, dimana Agent berusaha menyelesaikan maze secepat mungkin, hingga siap masuk ke dalam block reward -1.

Penambahan living penalty tidak harus didalam setiap langkah. Penjelasan diatas hanya untuk menyederhanakan konsep living penalty.
Anda dapat mendalami lebih jauh aplikasi dari MDP di link berikut: www.cs.uml.edu/ecg/uploads/AIfall14/MDPApplications3.pdf